





展望至2026年,企业数智化转型已进入深水区。人工智能(AI)的角色正经历一场深刻的演变,从辅助性的“聊天对话”工具,进化为深度嵌入业务流程、能够自主决策与执行的“智能体”(Agent)。在这场变革的浪潮中,一个核心挑战浮出水面:如何唤醒企业内部沉睡的海量非结构化数据?答案指向了基于向量化存储的RAG(检索增强生成)技术。它不仅是构建“企业大脑”的底层基石,更是我们正远科技引领企业实现从传统文档管理到智能化知识赋能跨越的核心路径。
范式转移:2026年AI开发的核心趋势
从通用大模型走向私域智能体
到2026年,AI开发的重心将发生决定性转移。企业追逐的不再是无所不知的通用大模型,而是能够深刻理解自身业务、精准解决垂直领域问题的专属智能体。通用模型虽然知识广博,但在面对企业内部复杂的工艺流程、特定的客户需求或严格的合规标准时,往往会因“知识隔离”而显得力不从心。它们的通用知识无法穿透企业的数据壁垒,为其独特的管理与运营提供真正有价值的洞察。因此,通过企业私域数据进行训练和增强,构建专属的、具备深度行业理解力的AI智能体,已成为不可逆转的趋势。
非结构化数据的“资产化”觉醒
在大多数企业中,超过80%的数据是非结构化或半结构化的,它们以管理文档、研发方案、设计图纸、会议纪要乃至视音频资料等形式散落在各个角落。在传统IT架构下,这些数据往往是难以利用的“沉默成本”。然而,随着AI技术的发展,企业管理者开始意识到,这些沉睡的数据恰恰是企业最宝贵的知识财富。如何激活它们,将其从成本转变为驱动决策与创新的核心资产?向量化存储技术提供了关键的钥匙,它能够搭建一座桥梁,连接这些原始、复杂的非结构化数据与AI的认知决策能力,是实现数据“资产化”的必经之路。
技术揭秘:向量化存储如何让AI“读懂”企业
什么是向量化存储(Embedding)?
从技术角度看,向量化存储(Embedding)是一个将复杂信息“降维”并“数学化”的过程。无论是文字、图片还是声音,都可以通过深度学习模型转化为一个由数百乃至数千个数字组成的“向量”。这个向量可以被看作是该信息在多维空间中的一个精确坐标。这个过程的革命性在于,它让计算机不再是机械地匹配字符,而是开始理解“语义”。
与传统的关键词搜索相比,其差异是根本性的。传统搜索只能找到包含“智能制造”这四个字完全匹配的文档;而基于向量的语义检索,则能同时找到讨论“工业4.0”、“自动化生产线”、“数字孪生”等概念上高度相关的资料,即便这些文档中并未出现“智能制造”一词。这种基于语义相似度的检索方式,其精准度和召回率远超传统方法,是让AI真正“读懂”企业知识的前提。
RAG(检索增强生成):解决AI“幻觉”的关键
大型语言模型一个广为人知的缺陷是“幻觉”——即在缺乏准确信息时,可能会编造看似合理但实则错误的答案。这对于要求严谨和准确的企业应用场景是不可接受的。检索增强生成(RAG)技术正是解决这一问题的有效路径。
在正远AI平台中,我们利用RAG技术构建了一个严谨的工作流:当AI接收到一个问题时,它并非直接开始“创作”答案,而是首先利用向量化检索技术,在企业专属的知识库中快速、精准地找到与问题最相关的资料片段。随后,它将这些经过验证的、源自企业内部的“事实”作为上下文,来组织和生成最终的回答。这一机制不仅极大地提升了AI回答的真实性、专业性与时效性,更重要的是,它让AI的每一个结论都有据可循,确保了业务决策的可靠性。
多模态能力的融合
企业的知识并非仅以文本形式存在。设计图纸、设备运行的监控视频、产线质检的图片、客户服务的语音通话记录……这些多模态数据同样蕴含着巨大的价值。一个先进的AI平台必须具备处理和理解这些多样化信息的能力。正远AI平台通过构建多模型协同架构,能够对文本、语音、图像等多种类型的数据进行统一的向量化处理,并将其纳入企业知识库。这意味着,你可以用一张设备故障的图片去检索相关的维修手册和历史案例,或者用一段客户的口头描述去匹配对应的产品解决方案。这种多模态能力的融合,让企业知识库变得更加立体和完整。
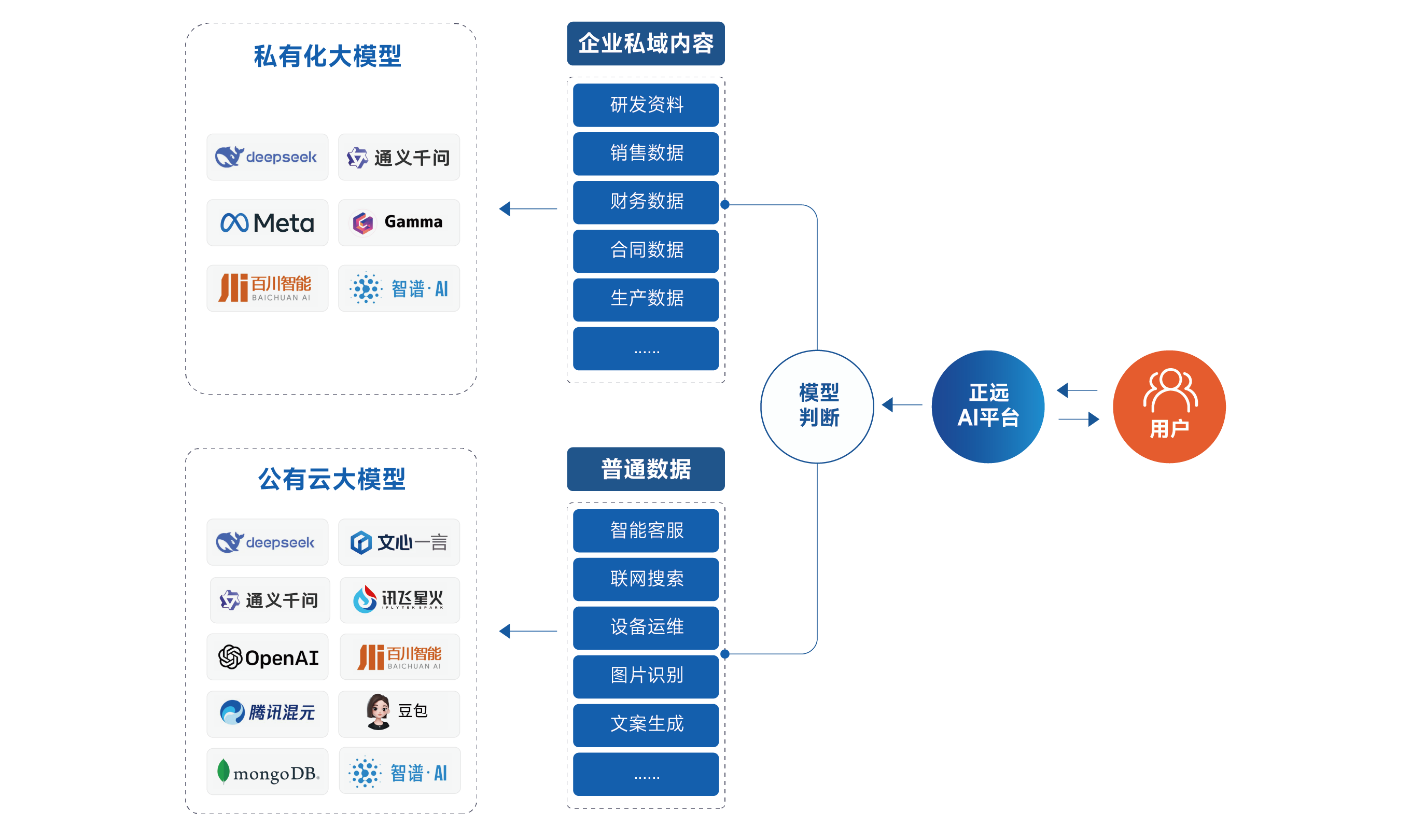
正远AI平台:构建安全可控的企业级知识库
“自主可控”是企业AI战略的基石
在拥抱AI带来的效率革命时,数据安全与隐私是任何企业都不能逾越的红线。将包含核心技术





