





在生成式AI(AIGC)浪潮下,企业构建专属的私域知识库已不再是可选项,而是构建核心竞争力的必然路径。通用大模型虽功能强大,但其知识截止日期和缺乏行业深度的“通病”,使其难以直接解决企业级的具体问题。检索增强生成(RAG)技术架构应运而生,它通过外挂知识库的方式,让大模型能精准调用企业内部数据。在这套架构中,向量数据库扮演着AI“长期记忆单元”的核心角色。本文旨在为企业决策者和技术架构师提供一份科学的选型指南,助力构建安全、高效的“企业大脑”。
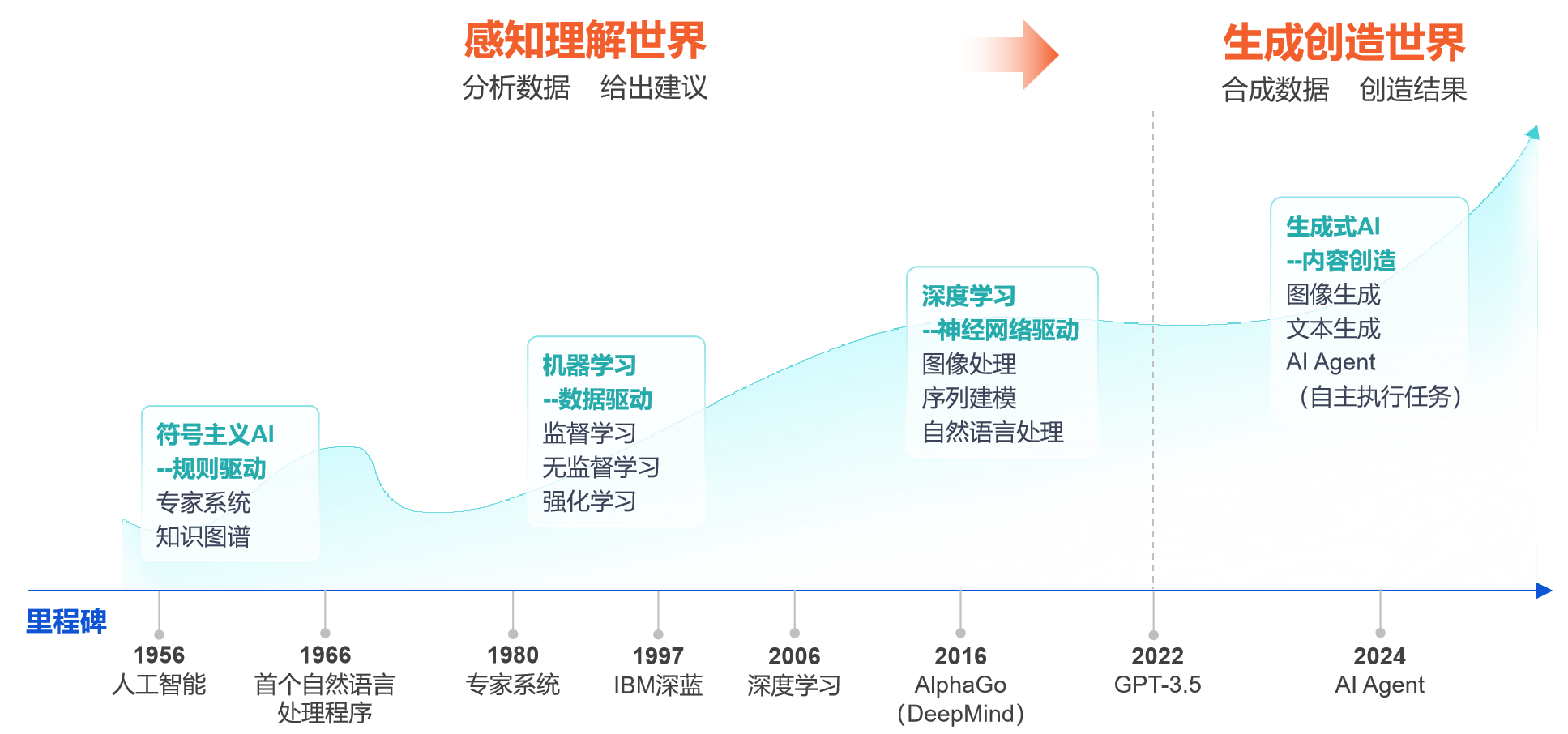
为什么向量数据库是AI开发平台的“逻辑基石”
大模型的局限性与知识更新瓶颈
通用大模型在面对企业级应用时,通常会暴露三个核心短板:首先是“幻觉”问题,即在缺乏相关知识时可能凭空捏造答案;其次是知识滞后,其预训练数据停留在过去某个时间点,无法获取最新的业务动态;最后,也是最关键的,是它不具备企业内部的私有知识上下文,例如产品手册、项目文档、客户服务记录等。这些局限性使得通用模型无法直接成为可靠的企业生产力工具。
RAG架构:让AI具备“查字典”的能力
RAG架构的核心思想,是让大模型在回答问题前,先去一个专门的知识库里“查资料”。这个过程的第一步是将企业的非结构化数据(如PDF、Word文档、图片)通过Embedding模型转化为数学意义上的向量。当用户提问时,系统同样将问题向量化,然后在向量数据库中进行高速相似度检索,找到与问题最相关的上下文信息。最后,将这些信息连同原始问题一起交给大模型,引导其生成更精准、更具事实依据的回答。
向量数据库在AI知识库中的关键角色
向量数据库正是这个“查字典”过程中不可或缺的“书架”。它的核心任务是高效存储和检索海量的特征向量。一个性能卓越的向量数据库,能够确保AI在处理复杂查询时,快速、准确地从数以亿计的文档片段中定位到最关键的信息。这不仅直接提升了AI响应的精准度,更重要的是,它将AI的回答与企业真实的业务场景紧密关联起来,使其真正具备解决实际问题的能力。
核心选型维度:如何科学评估向量数据库方案
为AI开发平台选择合适的向量数据库,需要从技术和业务双重角度进行系统性评估。我们在多年的数智化解决方案实践中,总结出以下四个关键维度。
性能与可扩展性
这是技术选型的首要指标。需要关注的核心数据包括:
- QPS(每秒查询数):衡量系统在高并发场景下的吞吐能力。
- 响应延迟:直接影响用户体验,特别是对于实时交互式AI应用。
- 索引构建速度:决定了新知识能够多快被系统吸收和利用。同时,必须评估其扩展能力。随着企业数据的不断积累,数据库是否支持平滑的横向扩展,以支撑未来可能达到PB级的数据存储需求,是决定其生命周期的关键。
数据持久化与一致性
企业级应用对数据的可靠性要求极高。所选的向量数据库方案必须具备完善的数据持久化机制,确保在系统宕机或意外中断后,数据能够完整恢复,不会丢失。同时,它需要保证数据在分布式环境下的读写一致性,满足企业级系统对稳定与可靠的严苛标准。
部署灵活性:云原生 vs 私有化部署
部署模式的选择直接关系到企业最核心的资产——数据安全。云原生方案提供了便捷的开箱即用体验和弹性伸缩能力,但对于金融、能源、政务等数据高度敏感的行业而言,将核心业务数据托管于公有云存在不可忽视的安全风险。因此,支持私有化部署是这类企业的刚性需求。它能将整个AI知识库和数据牢牢掌握在企业内部,实现真正的自主可控。
集成与易用性
一个优秀的向量数据库不仅自身性能要好,还要能方便地融入现有的技术生态。评估时需要考察其是否提供丰富的API和多语言SDK,能否与主流的深度学习框架(如TensorFlow, PyTorch)和大型语言模型无缝对接。这决定了开发团队的接入成本和后续的迭代效率。
主流向量数据库深度对比分析
市场上主流的向量数据库各具特色,企业应根据自身的技术实力、业务场景和安全要求进行选择。
开源标杆:Milvus 与 Weaviate
这两者是目前最受欢迎的开源向量数据库。它们功能强大,社区活跃,提供了高度的灵活性和可定制性。选择开源方案意味着企业对技术有更强的掌控力,能够进行深度优化以适应复杂的业务需求。当然,这也要求企业具备相应的技术运维团队来保障系统的稳定运行。
云原生代表:Pinecone
Pinecone是典型的SaaS(软件即服务)产品,它以全托管的形式提供了极致的易用性和便捷性。用户无需关心底层的运维和扩展问题,可以专注于上层应用的开发。这种模式非常适合追求敏-捷开发、希望快速验证业务模式的初创团队或中小型企业。
传统数据库扩展:pgvector (PostgreSQL)
对于已经深度使用PostgreSQL等关系型数据库的企业而言,pgvector这样的扩展插件提供了一条平滑过渡的路径。它允许在现有的数据库体系内增加向量检索能力,降低了引入新技术栈的复杂度和成本。但其性能和专业性在海量数据场景下,通常不及专门设计的向量数据库。
实战视角:正远AI平台如何构建高性能企业级知识库
理论选型最终要服务于业务实践。作为一家深耕行业20余年的数智化解决方案提供商,正远科技将理论与实践深度融合,打造了“正远AI平台”,为企业构建专属智能体提供了一套完整、可靠的解决方案。
正远AI平台:安全、开放、易用的核心优势
正远AI平台是一个集成了多模态大模型、企业级知识库、AI建模平台和AI运营平台的企业级AI开发中台。它致力于帮助企业在确保数据安全的前提下,轻松构建专属的AI应用,其核心优势在于我们将20年来服务500多家大中型客户的经验,沉淀为一套“安全、开放、易用”的全栈式AI能力体系。
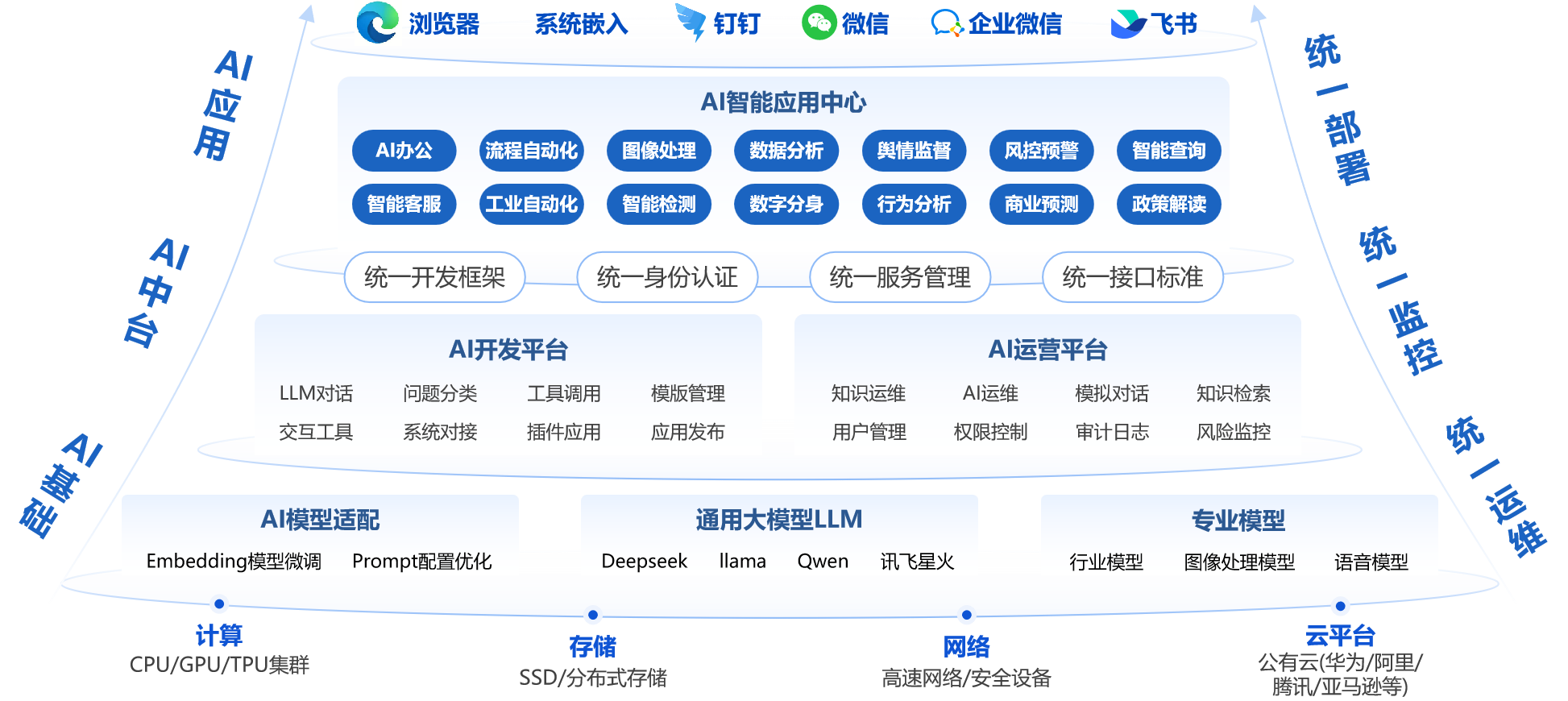
“企业大脑”的构建逻辑
我们认为,真正的“企业大脑”并非通用知识的简单堆砌,而是通用能力与企业私域智慧的深度融合。
- 多模态融合:企业的知识不仅存于文本。正远AI平台的多模态大模型能力,能够统一处理和理解文本、图像、语音等多种格式的数据,构建一个更加全面、立体的知识库。
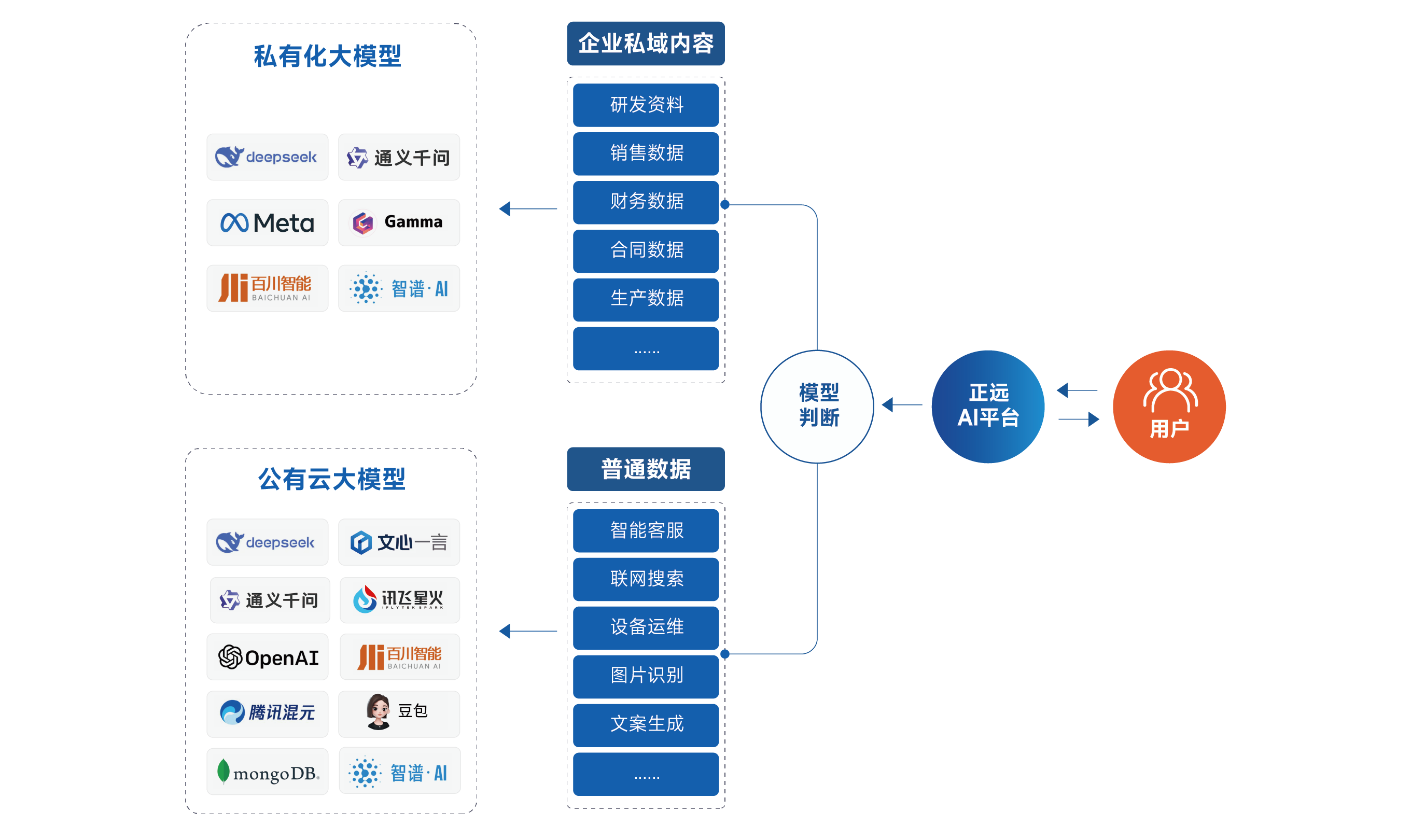
- 私域知识保护:我们始终将数据安全放在首位。平台支持完全的私有化部署,让企业的核心数据不出内网。通过将大模型的通用知识与企业的私域数据安全结合,我们帮助企业充分发挥自有数据的核心价值,同时避免了公有云方案的数据泄露风险。





